Production PDF Parsing for High-Stakes Financial Systems
February 22, 2026 · Alf Viktor Williamsen
Reading PDFs is a vital function of any application dealing with documents. Financial documents are commonly stored as PDFs (portable document format) because of the format's permanent nature and simple storage. PDF is a great format for humans. It has a natural print layout and an easy-to-digest way of structuring text content.
But one of the bottlenecks of PDFs is their difficulty of utilization by computers or intelligent systems such as LLMs. PDFs are best when "looked at", not when they are parsed by a machine. The analogy is clear: the PDF is for humans, not for computers.
Reality has it so that for more than a decade, PDFs have been the de facto standard for storing key information such as reports, accounting ledger summaries, information transfers, and more. This poses a challenge to anyone building a system that leverages PDF ingestion as part of its components.
In this article, I propose a three-step process for dealing with PDF files, and parsing key information from them, in a high-stakes financial system.
Setting the Scene
I have worked for over a year on a component of a system that deals with financial matters like thousand-plus row files for commission records. A common file size is 107+/- page PDF documents. The requirement is perfect extraction quality of key financial data points, which then get ingested into a downstream calculation component of the overall system.
Through trials and evaluations of parsing techniques, I have landed on a solution which I have complete trust in. Today, I will be sharing this system in depth.
Defining the Inputs and Outputs
In any system, defining the interfaces for each component makes data flow between components a smooth matter. Starting with the parsing requirements for the PDF parsing component is one of the most important decisions you make. Clearly defining the input and output requirements helps you reduce the inherent noise of data. Knowing exactly what you need from a file is the first step.
For this system, the PDF parsing component is required to output the following key data points:
- Agent number -- The identification of the sales agent from whom the parsed sales row is linked to
- Sales id -- Sales row identifier, for example, Sales #12345abc
- Product id -- "Car insurance, #999"
- Commission base -- The base amount, from which commission downstream gets computed with Python
- Commission amount -- Occasionally, the commission is pre-computed in the source file
- Period id -- Crucial identifier required in order to accept a sales row
- Commission rate -- Occasionally the rate is explicit in the source file
Having defined the exact data I need from a PDF, I can go about the business of building the parsing. Knowing exactly what I am after allows me to build a schema into the system that can be validated for each output of the parsing component. This prevents bad data from ever reaching the downstream components. Additionally, I can reject files up-front: if the files are not compatible with the required output (i.e., if the PDF is a news article or something unexpected), the parsing cancels immediately instead of initializing a full "dead" run.
Once I know clearly what I expect from this component, I can progress into designing the rest of the system.
Parsing Signal from Noise
Parsing PDF files is one of the most delightful problems in software systems. Inherently, the task of getting information from a PDF is all about extracting a clean signal (a specific data point) from the random and high-entropy nature of PDFs (unlimited formatting variations possible).
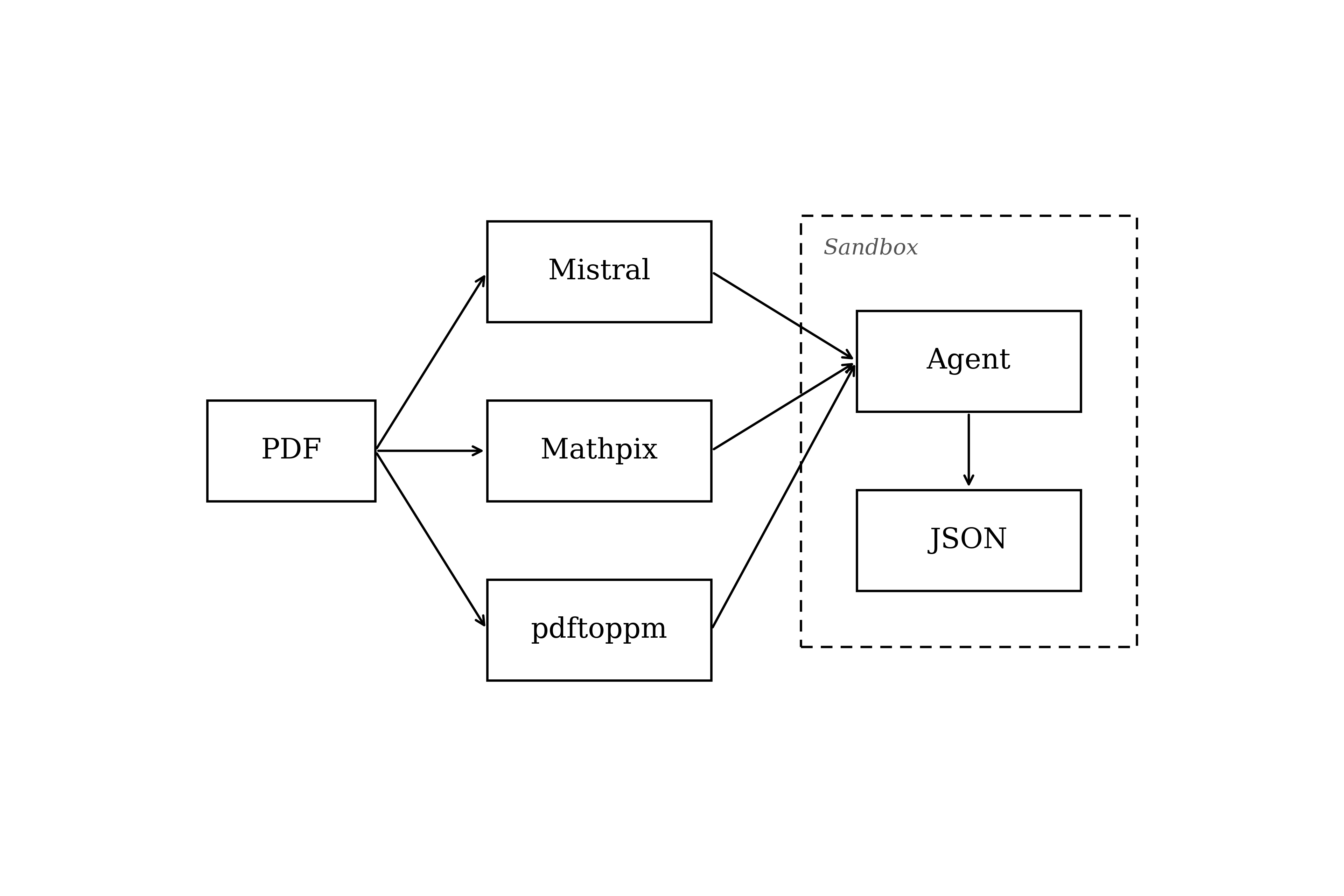
I favour three different parsing methods and services. Let's walk through each one, keeping in mind our schema and output requirements.
Mistral OCR API
The Mistral OCR API is a fast and reliable OCR machine learning model service where a user can ingest a PDF file of any form and sort, and get a structured output in markdown (plain text format without any formatting or styling) or JSON (JavaScript Object Notation). Both of these output formats are easy to parse and read by a computer, because both get rid of any unnecessary styling, metadata, and formatting, leaving you with only the words, text, and numbers.
The Mistral OCR API is a favourite of mine because of how fast you can go from zero to working system. The service allows large batch uploads and completion within seconds.
Thinking about how the Mistral OCR service fits into the system: the API allows you to parse any PDF, extract tables, get images, and extract the entire PDF contents into the two much cleaner formats mentioned.
From here, the clean and simple output is ready for the next step in the system, which I will talk more about below.
Mathpix
I believe in redundancy as a key property of any system, deeply integrated into the design from the very first initialization. This is why I choose to have an additional OCR-based service in utilization -- not just as a fallback for Mistral failures, but in synergy with Mistral. Mathpix is fundamentally different from Mistral in that it leans more heavily towards maths and tables. This is perfect for a financial system that requires complete accuracy. And, doing the maths on the probability of system failure, adding a second OCR tool exponentially reduces the probability of complete failure.
Mathpix is similar to Mistral in that you can upload a PDF and receive a structured, plain-text version of the PDF contents.
Getting specific: inside the Mathpix API there is a rather "hidden" boolean you can enable: enable_tables_fallback=true. This option enables what Mathpix calls "an advanced table processing algorithm that supports very large and complex tables." Thinking back to what our schema requirements are, and the types of files our PDF parsing component handles, enabling this option is a no-brainer for our 100+ page table-heavy files.
PDF to PNGs
To further bulletproof the system, I leverage the tool pdftoppm -- a CLI (command line interface) tool that runs locally to convert a PDF file into one PNG image screenshot per page. This is a very high-leverage tool in this system. The two previous parsing services allow us to rapidly extract the text and image content of the input files, but pdftoppm allows us to do further and more rigorous analysis of each page and its original structure.
From the command below, I get one PNG image per page, from where the system can easily review the specifics of each page:
pdftoppm -png -scale-to 1800 input.pdf output
-scale-to 1800 constrains the output image resolution to maximally 1800px on the tallest side, useful for consistency and for downstream API ingestion limitations which we will get to.
Putting It All Together
So far, I have talked about how to get information from a PDF file into a "friendly" format, more simply readable and understood by a computer. Once these parsers have done their job, we have the following pieces to work with:
- Mistral: cleaned markdown or JSON including extracted images
- Mathpix: clean markdown with additional "advanced" table extraction for edge cases and superior coverage for table-heavy files
- pdftoppm: one PNG screenshot per PDF page for deeper visual analysis of the original page structure
Orchestrating the Parsers
With these three parsed versions in hand, we can now orchestrate agents to do the inference of data from the PDF source file. We leverage a visual and text-based LLM model inside a sandbox running in the cloud to do this work, using the two current best tools for the job:
- Claude Agent SDK in Python
- E2B sandbox pre-built templates
Claude Agent SDK is a very powerful tool for processing data and getting a specific output. Once installed, the Claude Agent SDK bundles Claude Code's claude tool, which is the current best coding and computer agent available. Additionally, using Claude, you instantly get access to the best LLM models on the market.
E2B is a service for spawning ephemeral small virtual machines in the cloud. A virtual machine is like your desktop computer, but on a smaller scale and for a different use case. When using an E2B sandbox, we can allow the Claude Agent to do virtually anything to "its sandbox", because the only thing that matters is not what the agent does inside the sandbox, only what it produces and outputs from the work done inside of it.
Think of the sandbox as the "workshop" where the LLM has a range of tools (such as the three parsers we have talked about, and Python) and where it can break things, run experiments, and do virtually anything, without ever touching our application production code.
Instructing the Agent
Now that we have laid the foundation of the environment, we can begin instructing the Claude Agent on what we desire it to do. Here, we revisit the schema we defined earlier -- agent number, sales id, product id, commission base, commission amount, period id, and commission rate. These are the exact fields we need from any given PDF file, and they form the foundation of the instructions we give to the Claude Agent in the form of a formal document inside the sandbox -- the agent's "work requirements." This formal markdown (.md) document is similar to a document you hand to a co-worker when you need them to do a particular thing. The fewer questions the Agent might have about your document, the better the document is.
Think of this as the specific instructions covering:
How the agent will work. Exactly what steps it should take.
How the agent will create the output. Exactly how the desired output should look (use the schema rigorously).
What are common issues and things to know? How does the agent deal with failure? (i.e., if the file is not a financial document, or if a part of the system breaks)
These three points form the basis of a document which will be iterated on countless times through tests until the Claude Agent produces deterministically quality outputs. The Claude Agent is an LLM AI model, which means that the more specific and helpful you as the creator can be through the instructions, the more flawlessly the Agent can do the work for you.
Let me now outline how the Agent will do the work. I will not bore you with the full instructions, as these get long and specific for the system design requirements. By nature, your system will be of differing design, requiring a different set of instructions. But the following outline creates a high-quality, predictable set of examples you can build on.
Introduce how the component (the agent + sandbox) fits into the system:
- "You are reading a pre-parsed PDF file containing financial information."
- "You are a component part of a larger system processing commission sales records using Python for calculation."
- "Your task is to produce high-quality JSON extractions of a PDF file."
- "The JSON file you write is used downstream inside the next system component to store and do Python calculations on. Doing any calculation with the data is NOT your task."
Introduce the system environment:
- "You have three directories, each containing different parsing versions from the same file."
- "Use all three directories to produce the final JSON parsing of the sales rows containing complete verbatim-JSON-transformed extractions from the source file."
- "Use all three parsing versions in order to cross-verify the parsing of the file by processing each page in logical, self-determined chunks. Using all three parsing versions gives you a completely verifiable way of working, which is perfectly necessary for the complex financial data you are working with."
Define the expected output requirements and where it should be produced:
- "You will be validated using programmatic JSON validation that the final JSON file you write is valid. Therefore, follow the assigned JSON schema rigorously."
- "If you realize that the PDF source file will not be compatible with the assigned JSON schema, you simply escape and fail instantly. Failure is accepted if the file is clearly incompatible -- in fact, failure is desirable in such a scenario."
- "All final JSON outputs must be written to a file called output.json inside the output directory in your file environment."
Explain how to work and the minimum amount of verification until confidence can be produced:
- "Given the three versions of parsing, you should use all three versions iteratively to verify your inference of the data. This allows you to keep the data quality high."
How to deal with large samples:
- "By running the tool estimate_tokens.py you can instantly get a recommendation as to how you can work with the assigned files. If the tool output is over the red line, you must spawn a team of agents and assign work specifically, with perfect overlap, and create rigorous validation for the final end product written to the output directory."
- "Each agent writes their own JSON files, from where you do the merging once ALL data has been processed. If a part of the data fails, or you get stuck somewhere, you must fail quickly instead of trying to fix a massive run."
How to deal with failure gracefully:
- "Simple failures are tolerated and should simply be ignored. For example, a tool use failure or similar -- if this happens, simply write your own tools on demand."
- "Be flexible with the approach, but rigid in the output."
Specific first steps:
- "Start first with checking the size of the assigned work. This will inform whether you can do the work alone, or if you need to spawn an agent team."
- "Always prefer creating an agent team, versus using sub-agents, when it comes to specifically dealing with writing outputs and processing files."
Making It Work
The above system is a result of trying and experimenting with countless approaches to the problem of dealing with PDFs. I believe this system produces a predictable and satisfactory solution.
In integrating this into the overall system, I have had success processing high-risk financial information like commission data with accuracy. Dealing with, and handling the risks of, inaccurate or false data extraction is my worst nightmare. Hence, this system design aims to eliminate such risks through cross-verification, frontier LLM models, and validations.
Because of the nature of PDFs, it is impossible to create a perfectly deterministic solution when one does not know what the PDFs will look like. The system above is designed specifically to solve the requirement of being able to read and process any incoming PDF containing financial data. Once tested to a sufficient degree, and error-corrected through iterative design as per your system requirements, this system delivers a satisfactory result.