Giving an LLM Full Database Access Is the Right Call, and Here’s the Specific Design That Makes It Safe
March 6, 2026 · Alf Viktor Williamsen
One of the most exciting applications of LLMs I've worked with is giving an agent full access to run commands on a database. It allows the assistant to see the full picture: our data, settings, configurations, specifics. It fundamentally alters how the application functions and how good the outputs are.
But letting an agent have a full connection to your database is dangerous for obvious reasons. Agents can accidentally alter data without permission. So the challenge is: how do you give an LLM the full read picture while air-gapping it from accidental writes?
The answer is two connection strings.
All Commission Data Through One Agent
I built a platform for managing commission distribution at insurance firms. Sales, employees, agents, products, all in one Postgres database. Users manage commission flows from carrier to sales agent. The platform handles a dense stream of data: commission rates, agent information, performance analytics.
Users can navigate the UI manually. But the full capacity unlocks when an LLM agent works on behalf of the user. A task like migrating a commission rate across every configured agent, painful in a spreadsheet, trivial for the agent.
The system needs three foundational pieces to make this work.
Schema, Strings, and a Map
First, a schema that fits the application. Different apps need different schemas. An ecommerce store is fundamentally different from a commission distribution system, so the way you schematize your database is a contained problem for your specific app.
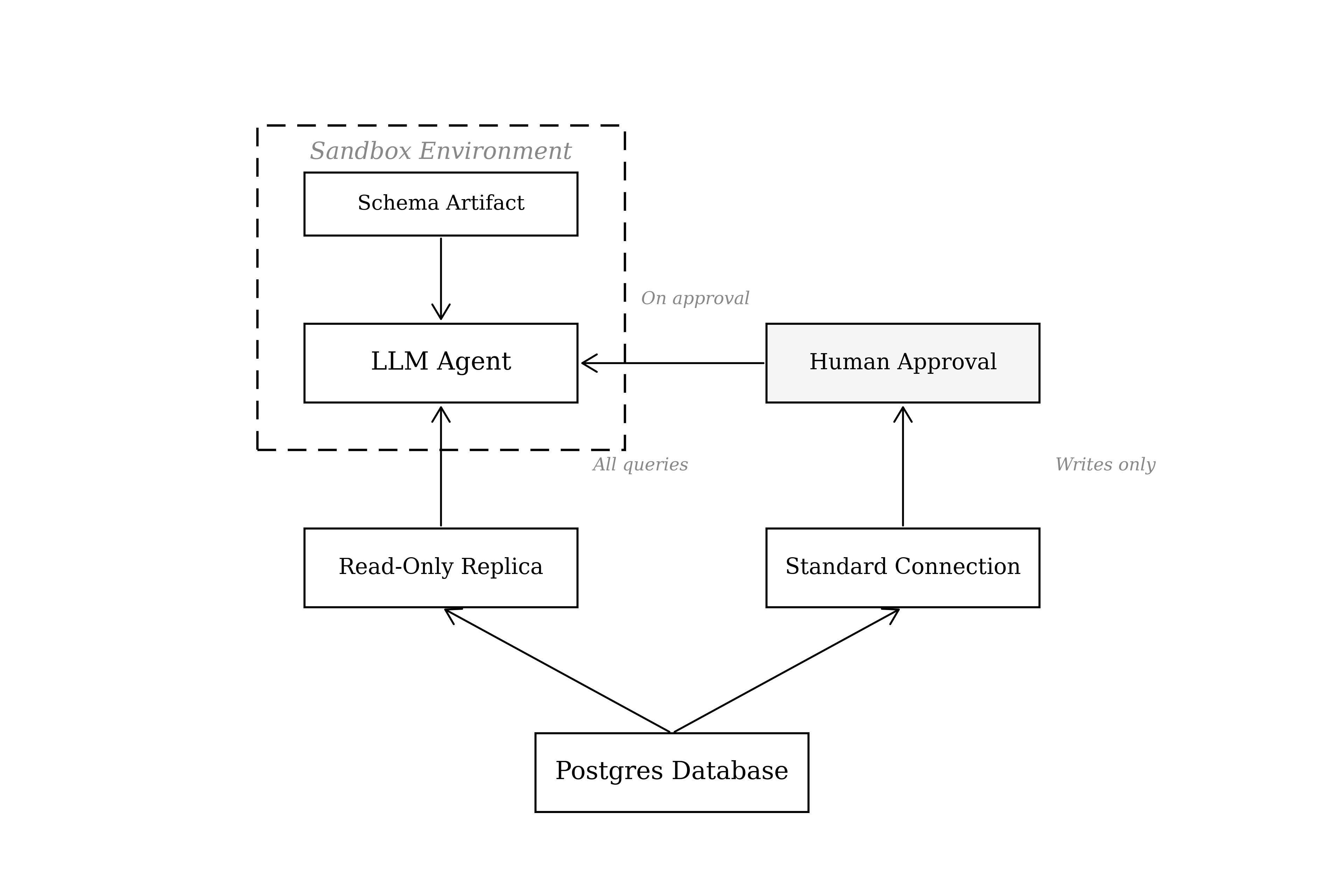
Second, two connection strings. The first is a read-only replica. This is the string the LLM uses for all queries that are not approved edits. The second is a standard connection string with write access, gated behind explicit human approval. This separation is the core of the design. It guarantees the agent can never run edits without approval, no matter what it generates.
Third, a continuously updated plain-text artifact of the schema, a markdown document describing every table, column, and relationship. This is what allows the LLM to instantly understand your specific database and write correct SQL against it. Without it, the LLM makes dumb errors.
Query Without Risk
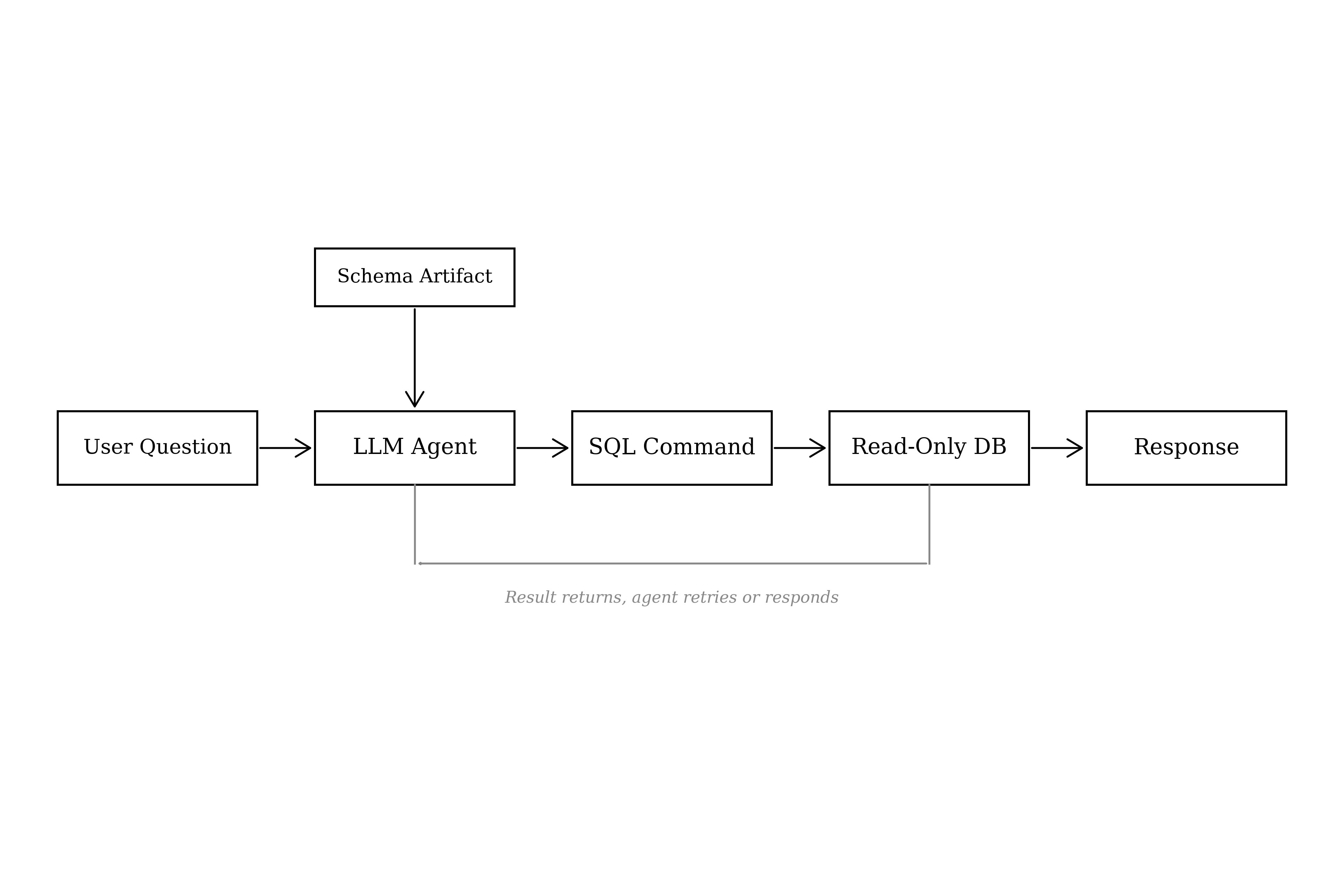
Here's how a query flows through the system. The user asks a question in a chat interface:
"What does sales amount to in January?"
The agent receives the question, references the schema artifact, and writes a SQL command:
The agent executes that command against the read-only connection. The database returns:
The agent then writes the response in plain language:
"Sales in January totaled $452,839.50."
The full loop (receive question, write SQL, execute, return answer) takes roughly ten seconds. Each step is one LLM call. The agent receives the user question and writes the SQL. The database result triggers a second call, now containing the returned data. The agent then decides: retry with a different query, or write the final reply.
Writes Only on Approval
Now for the dangerous part: edits.
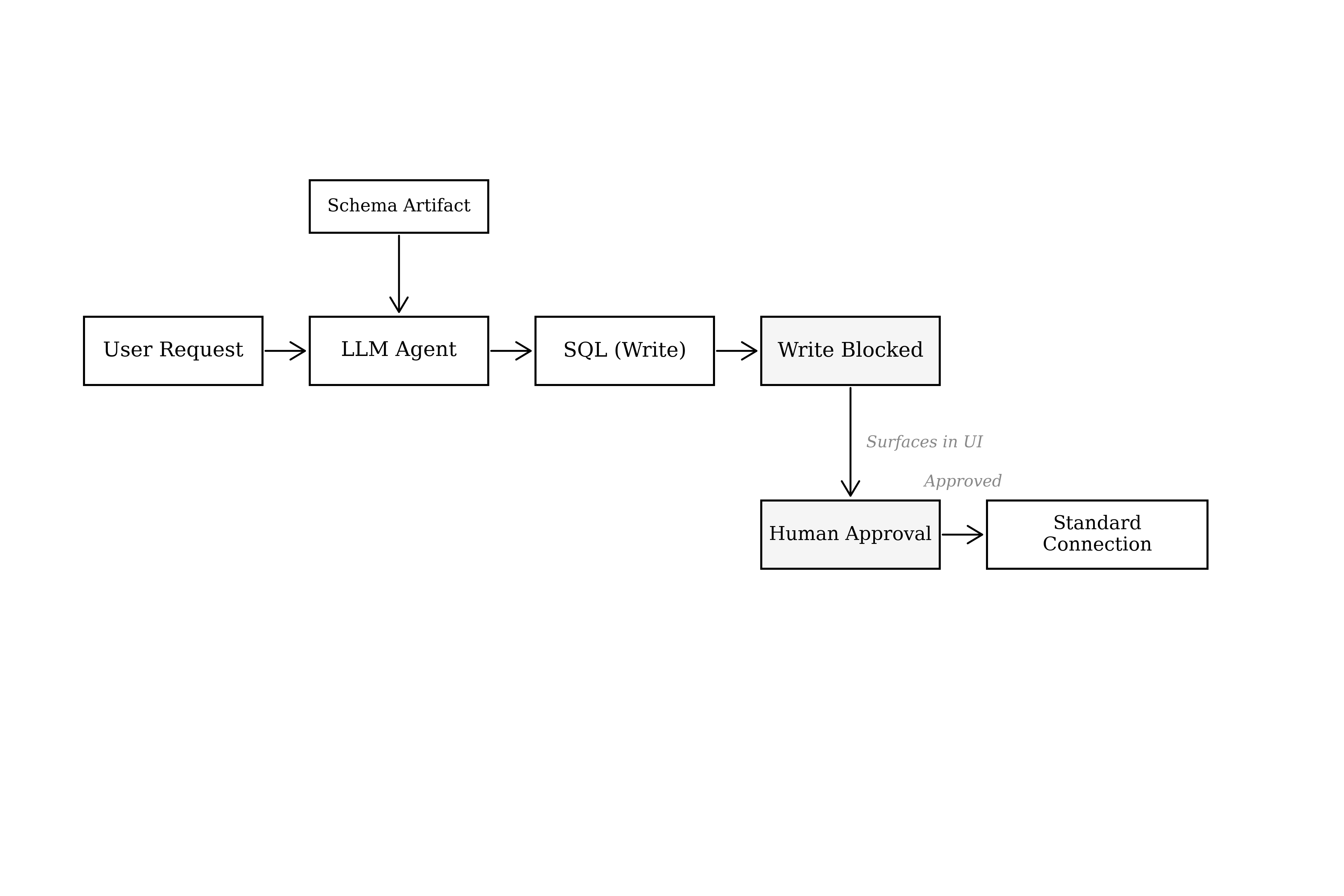
When a user asks for an action that requires modifying data, the agent runs through the same loop but against the read-only string. The system identifies when the generated SQL contains a write operation (INSERT, UPDATE, DELETE), blocks it from executing, and surfaces the proposed SQL in the user interface for explicit approval.
Only on human approval does the system switch to the standard connection string and execute the write.
This is a simple design, but it's the most effective one I've found. The read-only replica makes it physically impossible for the agent to alter data during its reasoning and exploration. The approval gate on the write string means edits only happen with informed human consent. Two connection strings, one architectural guarantee: the agent cannot break what it hasn't been allowed to touch.
Restriction Makes Agents Dumb
LLMs are probabilistic machines. They can generate completely random, potentially harmful SQL. The instinct is to restrict their access: limit what tables they can see, constrain what queries they can write. But restriction makes the agent dumber. It loses context. It can't answer questions about data it can't see.
The better path is full read access with an air-gapped write path. Let the agent see everything. Let it explore, join, aggregate, analyze. Then gate the single dangerous action, writing, behind a human checkpoint. You get the full intelligence of the agent without the risk.